Chapter 3 Data
3.1 Sources
Data used in this project was originally collected by a team based in California State University San Marcos, and led by Dr. Dustin Calvillo. A visit to his Google Scholar profile indicates that his recent research has focused on employing quantitative methods from cognitive psychology to the study of contemporary communication phenomena, especially mis- and disinformation.
This specific data set – the fake news and confirmation bias – is part of the Confirmation bias in fact checking political claims research project. There is a similar dataset in the same project, which is apparently a previous version of the one used in this project (suffixes x1 and x2, respectively. Although both datasets share the same variables, a few are present in one and not in the other. For example, “disconfirm_bias” is present in x1, but not in x2; the opposite is true for “ideology” and “condition” (referring to “fact-checking conditions”). More clarification was requested via email to the principal investigator, but we are assuming that x2 is a more refined version of x1, so we opted to use the former for our analysis.
The dataset has 247 observations of 53 variables, all of which are “double.” However, the data dictionary indicates that many of those represent other types of data and have possibly been transformed by the authors before publishing the data set. For example, the variable pol_party originally has values “Democrat” and “Repubican,” which are now represented by 1 and 2, respectively; gender originally accepted values “female,” “male,” “other,” and “decline to state,” and now are coded from 1 to 4, in that order. Others are originally integers, for example, t_concordant, which represents “total number f fact-checks for true politically concordant headlines.” The same is true for the Likert-type scale variable ideology, whose rating ranges from 1 to 7, “from extremely liberal to extremely conservative.” A third class that was present in the original dataset was “time,” the case, for example, of T_dem_rt (“mean reading time for true pro-liberal headlines”). Lastly, there are 2 variables that gorup other variables: CRT```` is the “total number of CRT items answered correctly” (0-6); andAOT```, which is the mean of items in the “active open-minded thinking” (1-5).
One possible challenge that may arise as we start the exploratory data analysis is the transformation of time values form doubles to time and date format. In terms of missing values, although the data set seems to have been pre-processed in order to exclude NAs, there are 4 observations that contain missing values (1 NA each).
3.2 Cleaning / transformation
#Add participant id
dataset$participant_id=1:nrow(dataset)
#Define a factor converter to convert numeric columns to factors
factor_converter = function(data,columns){
for (x in columns){
data[,x]=as.factor(data[,x])
data[,x]=addNA(data[,x])
}
return(data)
}First, the data set is loaded in using the package Haven’s read_sav() function, as the data is stored as a .SAV file. This type of file is outputted by the application SPSS. It is then converted to a data frame for easier use. The authors of this study clearly spent time preparing their data for publishing and little transformation was needed. Upon examination, there are many categorical variables which have already been modified to be numeric, ordinal variables. However, they are still numeric and plotting in ggplot2 often requires ordinal variables to be in factor form. As such, many columns will need to be converted to factors. This is done with a custom function factor_converter() which takes columns and a data set as a inputs and creates factor level variables, including an NA factor. One option to explore is modifying some of these ordinal variables to be binary, as using ordinal scale on data that shouldn’t be ranked can obscure true relationships. Given this data relates to individual participants and their responses in the study, a new variable participant_id has been added to the data set to uniquely identify each participant. This allowed us to track whether any anomalies were related to specific individuals. For now, this allows us to move straight into exploratory data analysis.
3.3 Missing value analysis
The authors mention that missing values have been removed prior to the data being made publicly available. However, there do seem to be a few missing observations present in the data. First we present the four variables that are missing in the data set and the overall distribution of scores for participants on these questions.
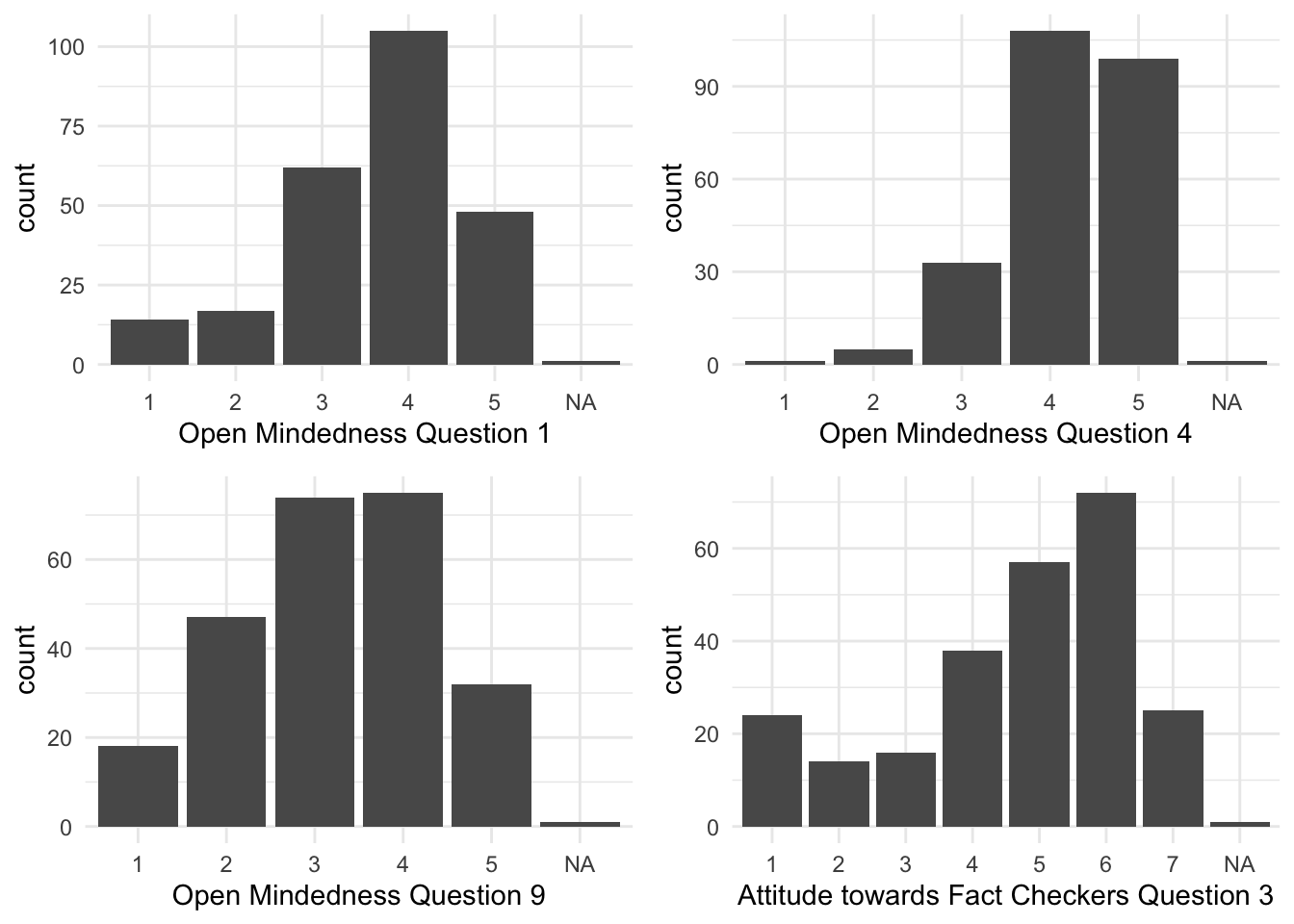
Overall, open minded thinking questions one and four received high scores among the majority of participants, while scores were slightly more widespread for question nine. The overall score for participant attitude toward fact checkers based on question three is also high. We now show below only the participants and columns that contained missing values to see if there were any similarities:
Variables:
aot: mean rating for 11 actively open-minding thinking questions (possible range of 1-5)
aaf: mean rating for three attitude toward fact-checkers questions (possible range of 1-7)
fc_att3: response to the third item on the attitudes toward fact-checkers scale (possible range of 1-7)
aot01: response to the first item on the actively open-minded thinking scale (1-5)
aot04: response to the fourth item on the actively open-minded thinking scale (1-5)
aot09: response to the nineth item on the actively open-minded thinking scale (1-5)
## participant_id aot01 aot04 aot09 fc_att3
## 1 4 4 4 NA
## 197 3 4 NA 3
## 213 NA 4 2 5
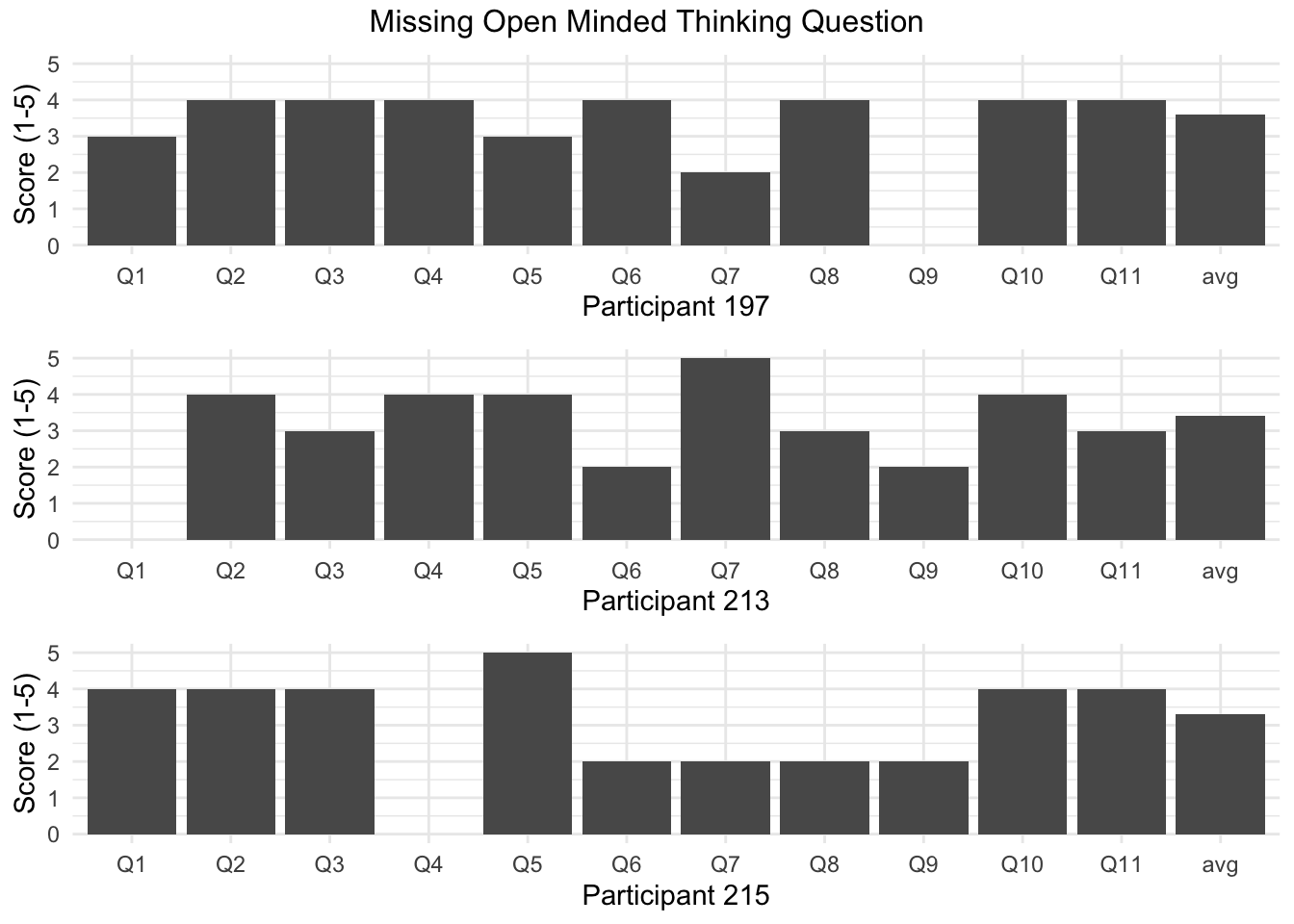
## 215 4 NA 2 3All four participants had a different column item missing, meaning they all had one blank response to a different question. This leads us naturally to investigate further whether these participants are similar across some other dimension.
## id aot01 aot04 aot09 fc_att3 gender pol_party ideology condition age aot aaf
## 1 4 4 4 NA female democrat 2 easy 34 3.64 4.50
## 197 3 4 NA 3 female republican 7 difficult 69 3.60 3.33
## 213 NA 4 2 5 male republican 5 difficult 26 3.40 4.33
## 215 4 NA 2 3 female republican 7 difficult 77 3.30 2.33There seems to be little in common among the four participants at first glance. However, all four score roughly a 3.5 on the AOT mean rating for 11 actively open minded thinking questions. Considering the scale goes up to only five, this means these participants were on the higher end in terms of their willingness to explore alternate ways of thinking. Considering aot01, aot04, and aot09 are all questions intended to judge open minded thinking, it’s possible that these participants believed the question was neutral, that it was outside of their realm of knowledge, or that they just couldn’t think of a black and white answer so they left it blank. But, it must be noted that all three participants missing an open minded thinking question are republican and two have the highest ideology rating, meaning they are extremely conservative (participants 197 and 215). Perhaps a question was asked that disagreed with them morally, such as abortion or the death penalty. This may have led them to give no response to this question. This theory can better be confirmed by the fact that participant 215 was not very open minded in regards to the ninth question, aot09, and only scored a 2 out of 5. Participant 197 chose not to answer this question at all. This is further backed up by the fact that responses to question nine are more widespread than the other questions, it could easily be a polarizing question between parties. Both also scored relatively low on questions intended to gauge the participants attitudes towards fact checkers, 2 and 3 out of 7 respectively. Maybe they felt uncomfortable sharing their views with the the proctor. Another idea could be that these three participants simply had a hard time answering these questions because the fact checking conditions were difficult. This may have made them more guarded in terms of their willingness to answer these type of questions.
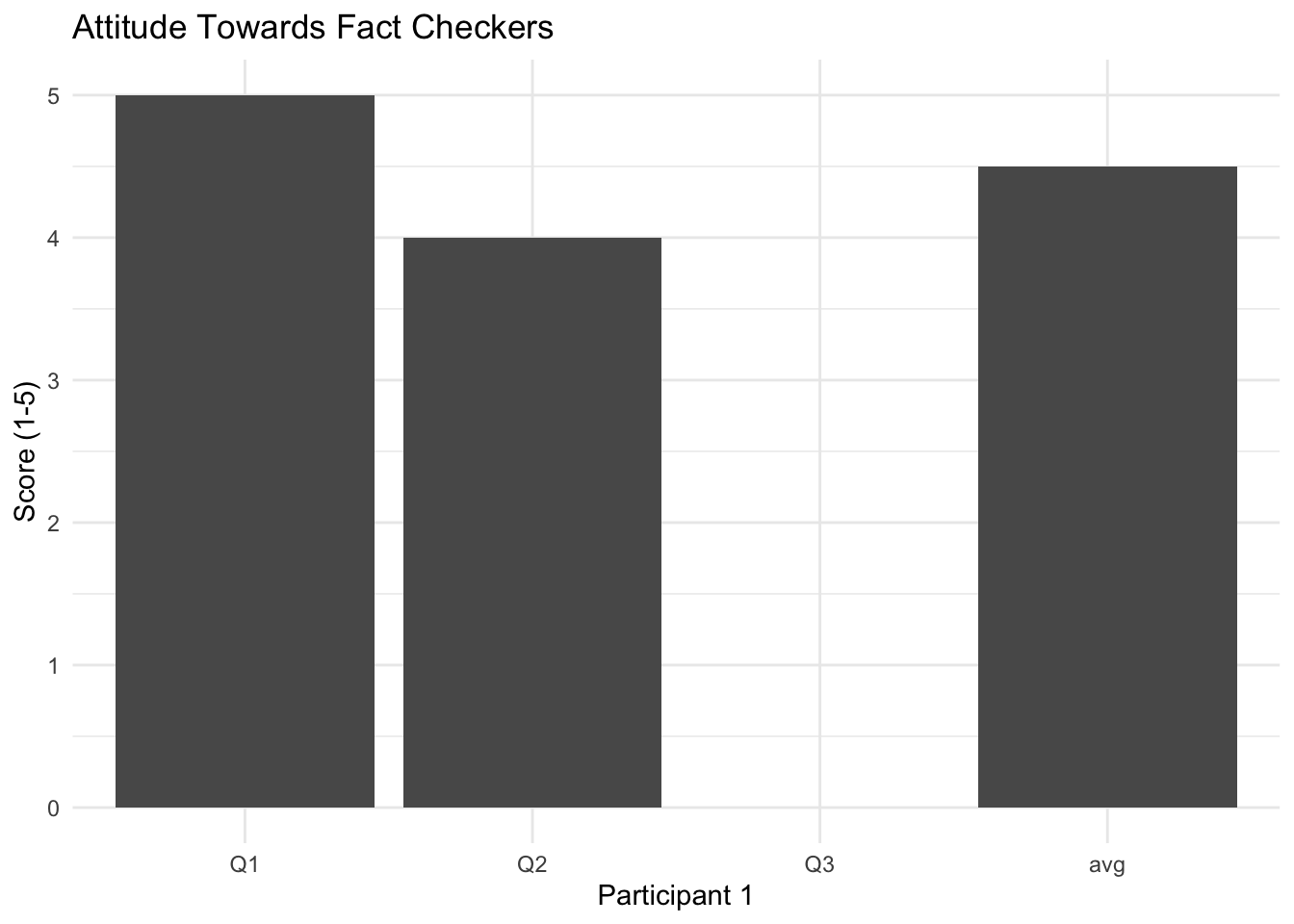
As for participant 1, she is a democrat who is extremely liberal with an ideology score of 2, with one being extremely liberal. fc_att3 was one of the questions given to participants to gauge their attitudes toward fact checkers. Overall, participant 1 scored relatively high in terms of her attitude toward fact checkers, with an aaf of 4.5/7. So it seems that overall she felt positively about fact checkers, but maybe she just didn’t feel that question was appropriate. All four are still valid participants to include in the study considering all So it makes sense the author is left on itother questions were answered.